
Modelos Locales
Una de las características más potentes de LoneWriter es su capacidad para funcionar de forma privada utilizando modelos que se ejecutan en su propio ordenador.
Al utilizar un modelo local, los textos no salen de su equipo y no se requiere conexión a internet para el uso de la inteligencia artificial.
Opción A: Ollama
Ollama es la herramienta recomendada para ejecutar modelos de inteligencia artificial en Windows, Mac o Linux de forma sencilla y eficiente.
Pasos para la configuración:
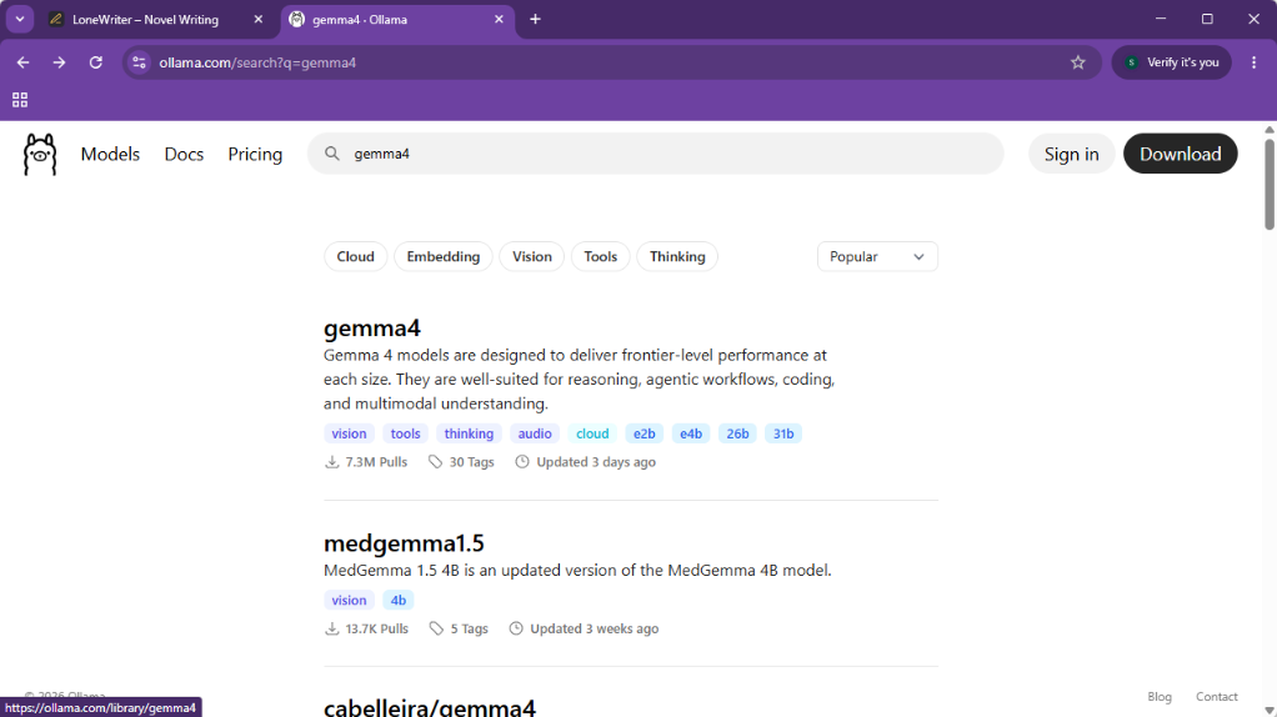
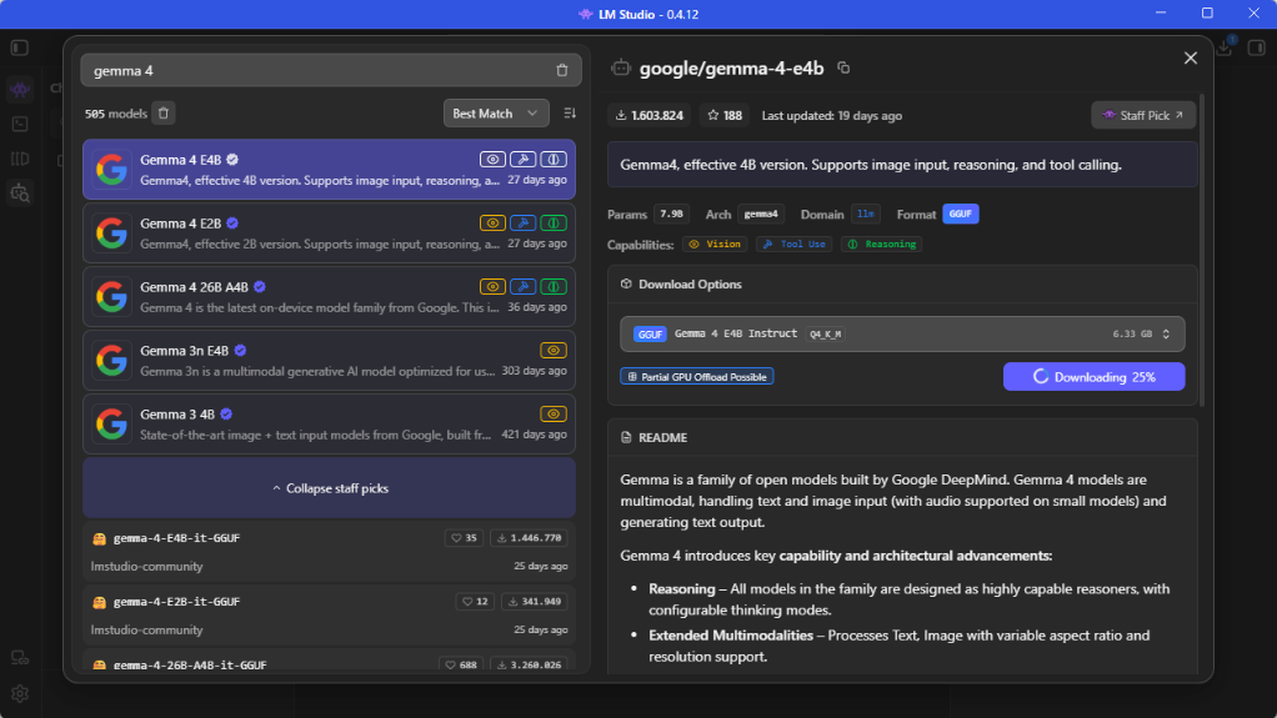
- Busca el modelo que quieras ejecutar en la web oficial de Ollama. En nuestro ejemplo, utilizaremos Gemma 4.
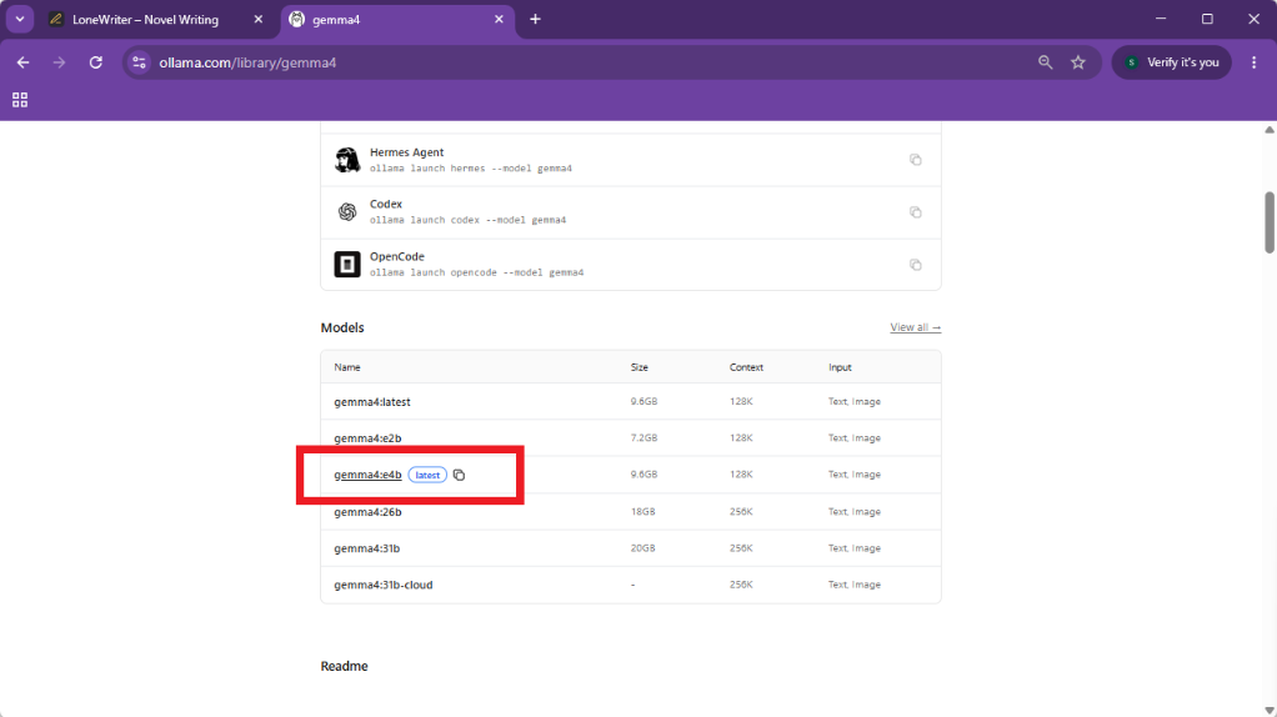
- En la ficha del modelo, selecciona y copia el Model ID con los parámetros que mejor se adapten a tu hardware (ej.
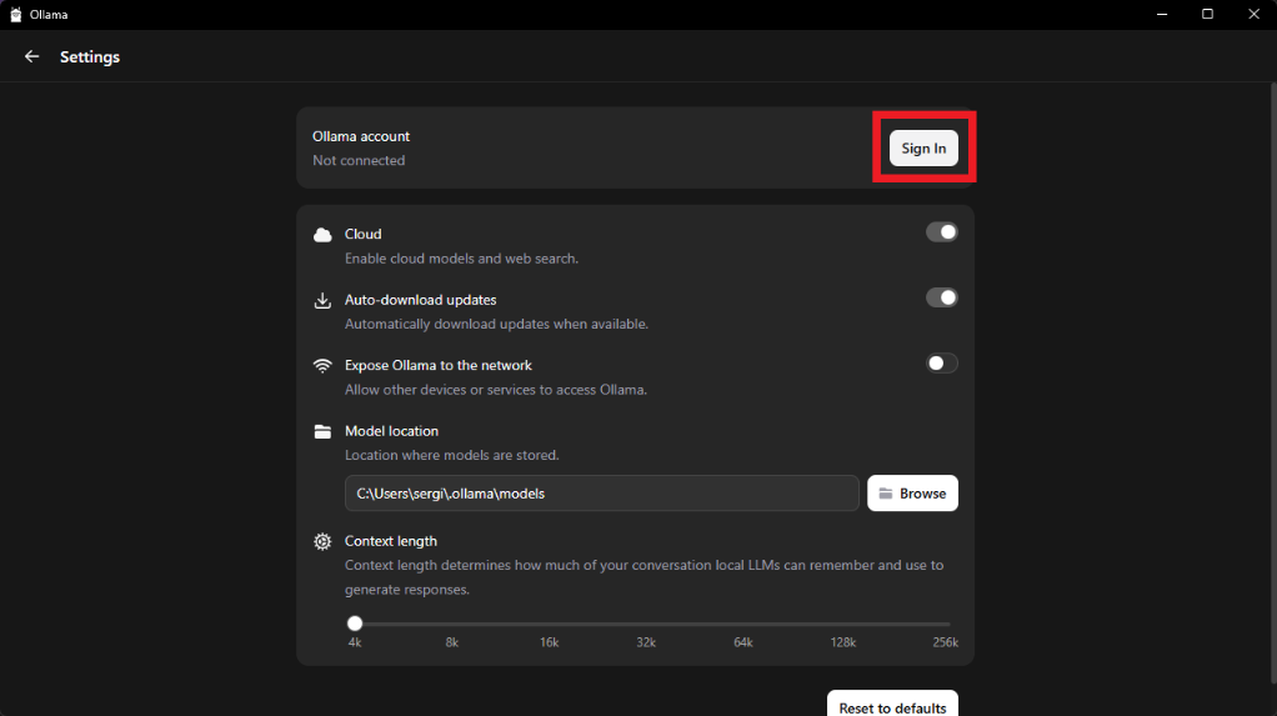
gemma4:e4b). - Una vez descargado e instalado Ollama, ve a la sección Settings y haz login con tu cuenta.
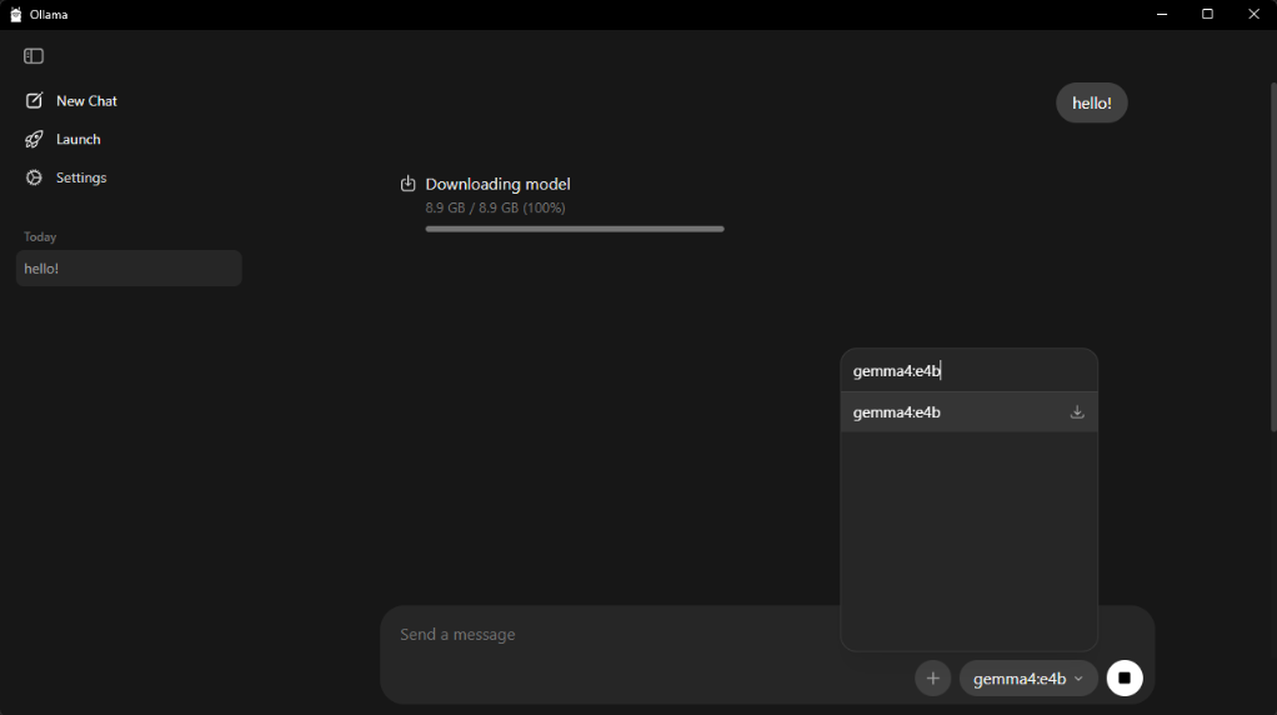
- Con la sesión iniciada, busca el modelo con el ID que has copiado previamente y descárgalo directamente desde la aplicación de Ollama. Es necesario iniciar un chat con cualquier mensaje para "forzar" la descarga del modelo.
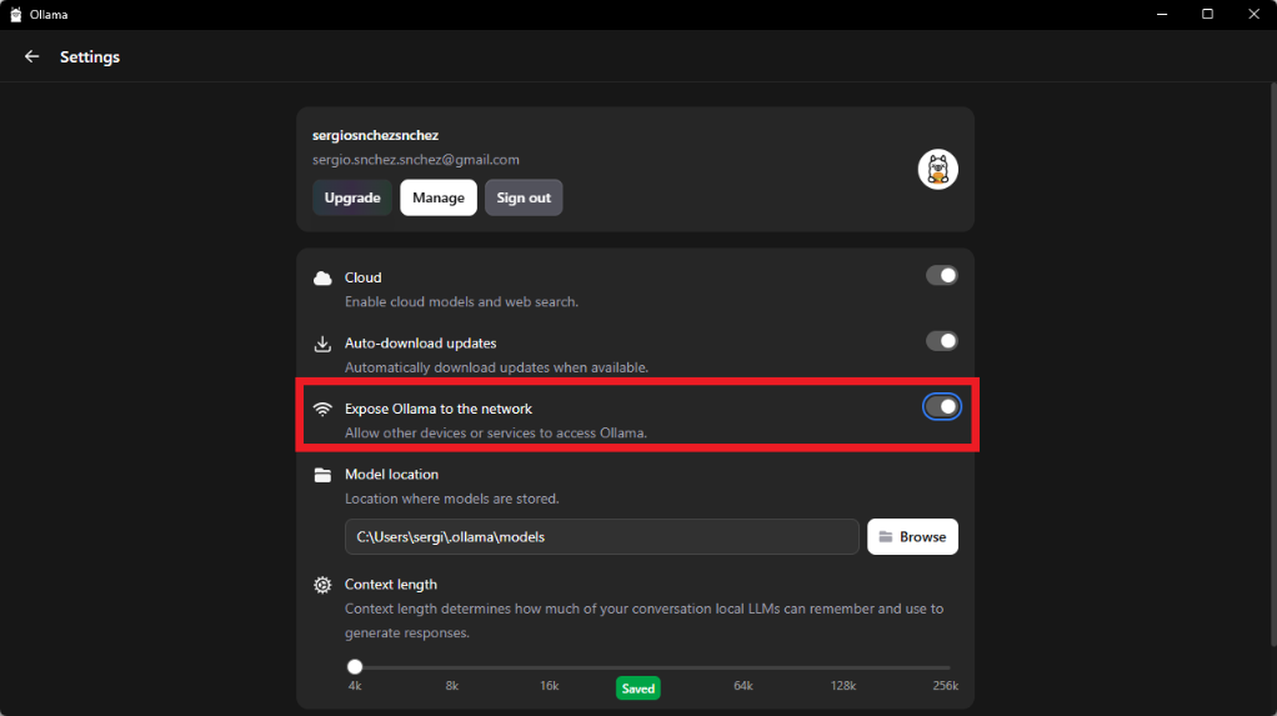
- Finalmente, en los ajustes (Settings), activa la opción "Expose Ollama to the network" para permitir que LoneWriter se comunique con el servidor.
- Por último, copia en LoneWriter el Model ID y la URL del servidor (asegurando que finalice en
/v1).
Conexión con LoneWriter:
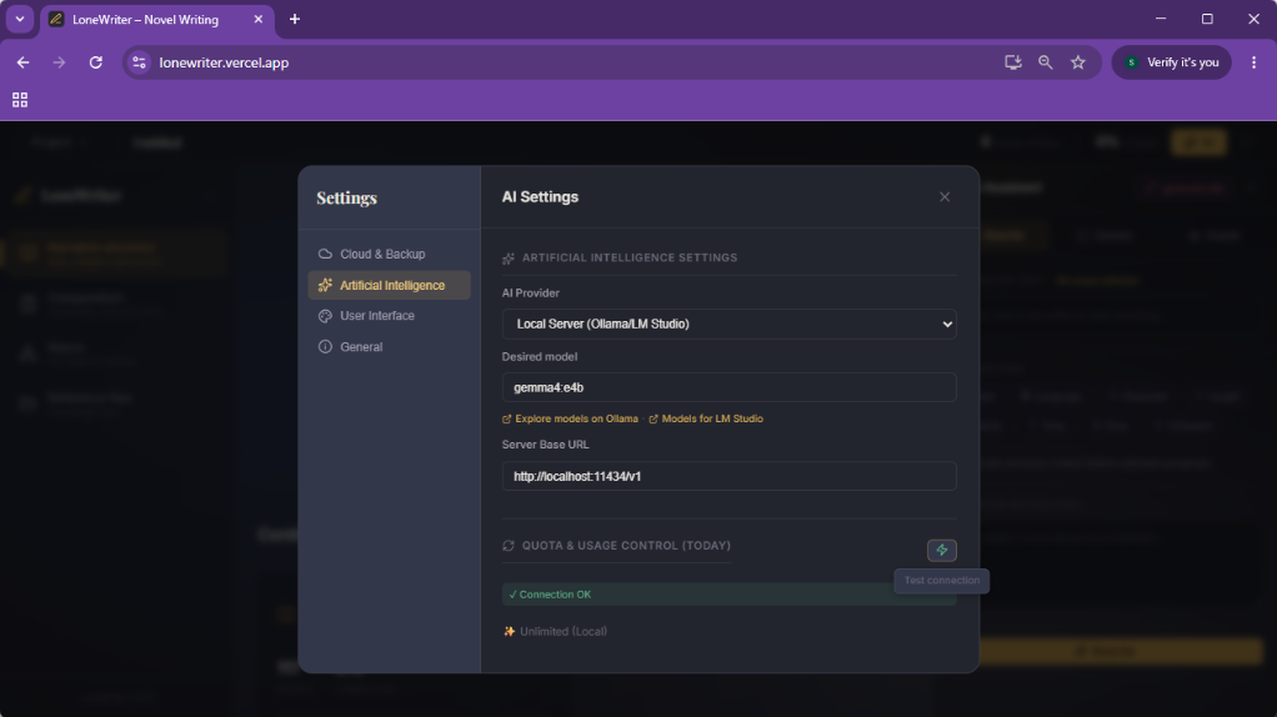
- En LoneWriter, ve a Ajustes > Inteligencia Artificial.
- Selecciona el proveedor Local.
- En el campo Servidor URL, verifica que aparezca:
http://localhost:11434/v1(o usahttp://127.0.0.1:11434/v1como alternativa). - En el campo Modelo, introduce el ID exacto (ej.
gemma4:e4b). - Asegúrate de que la URL finalice en
/v1si has introducido la dirección manualmente. - Confirma la conexión pulsando el botón de prueba.

Opción B: LM Studio
LM Studio ofrece una interfaz gráfica avanzada para descargar y gestionar modelos GGUF, ideal para quienes prefieren no utilizar la terminal.
Pasos para la configuración:
- Una vez descargado e instalado LM Studio, busca el modelo deseado (ej. Gemma 4) en la pantalla principal y descárgalo.
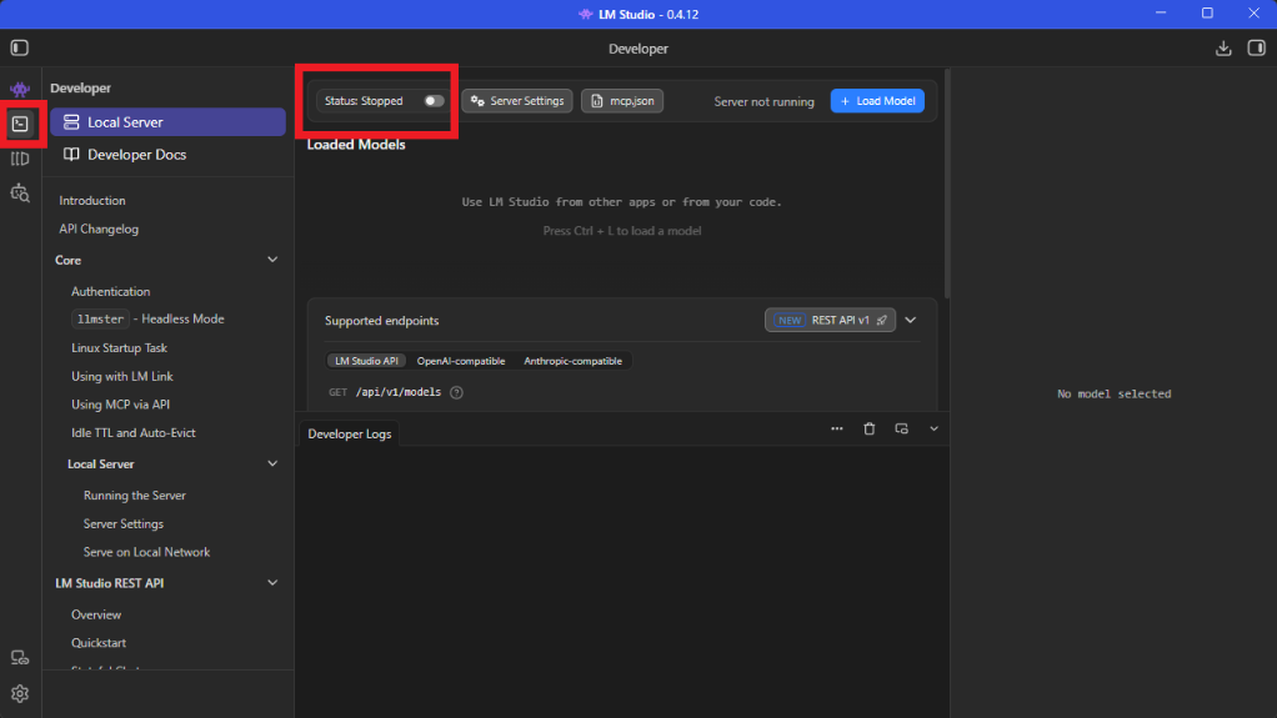
- Con el modelo descargado, entra en la sección Developer desde el menú lateral izquierdo (icono de la terminal) y activa el Servidor Local.
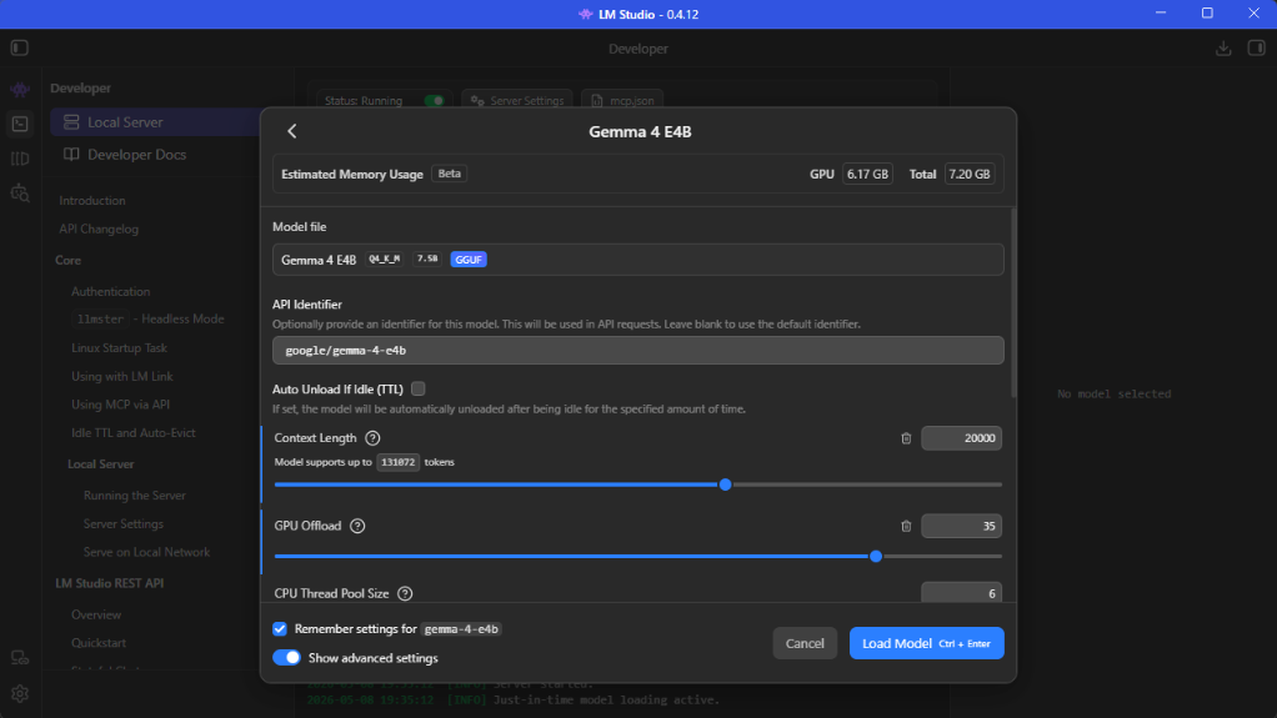
- Pulsa en Load Model para cargar y seleccionar uno de los modelos que hayas descargado.
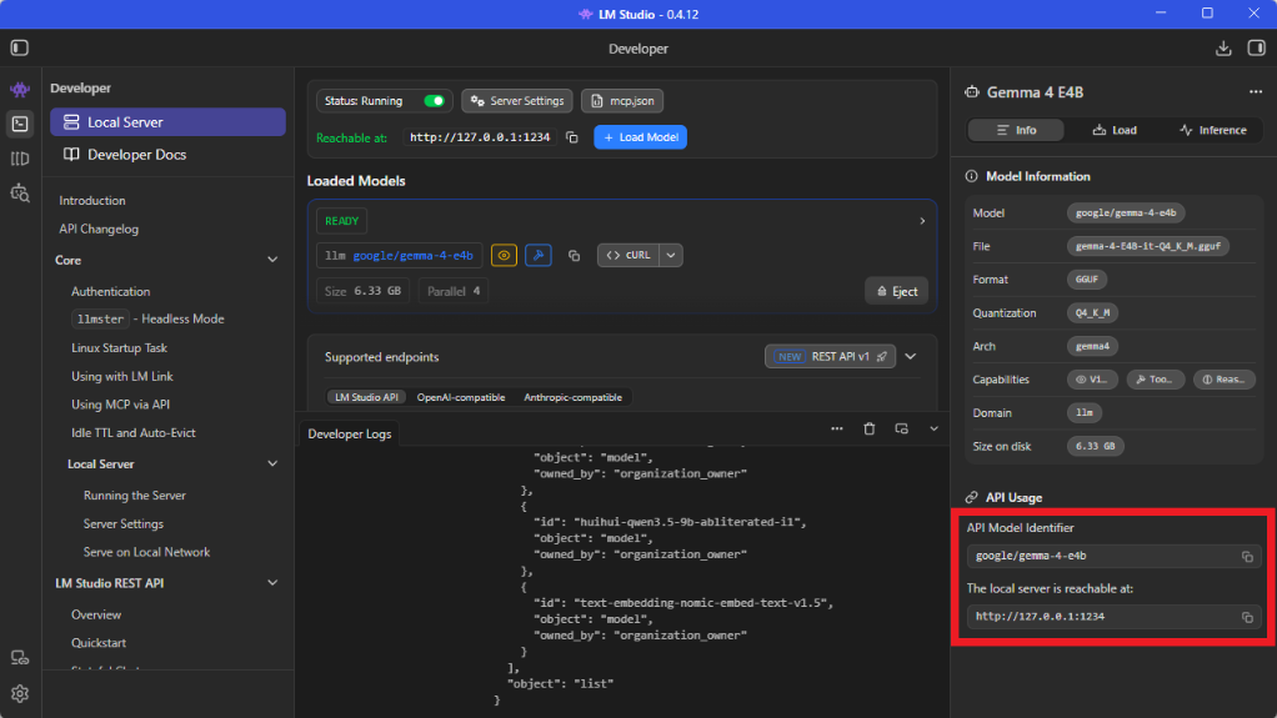
- Una vez cargado el modelo, puedes copiar el API Model Identifier y la URL del servidor local desde el panel derecho.
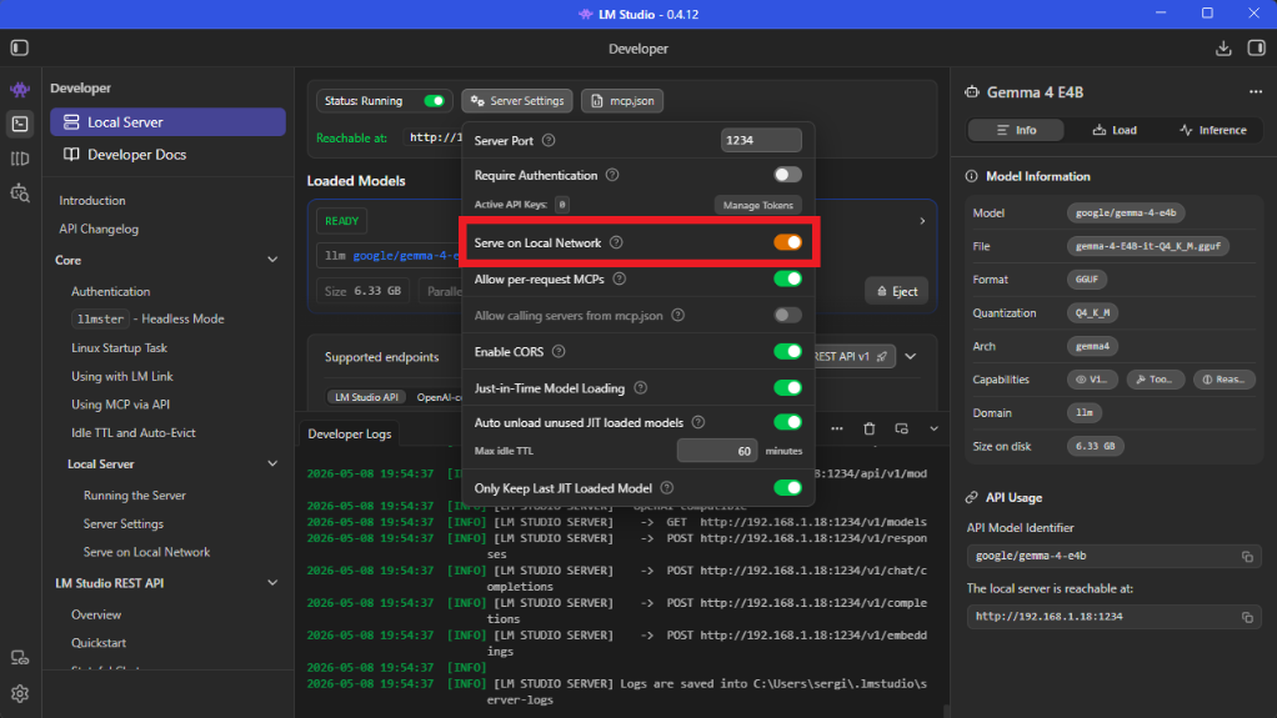
- Es muy recomendable activar la opción "Serve on Local Network" en los ajustes del servidor para asegurar una comunicación fluida con el navegador.
Conexión con LoneWriter:
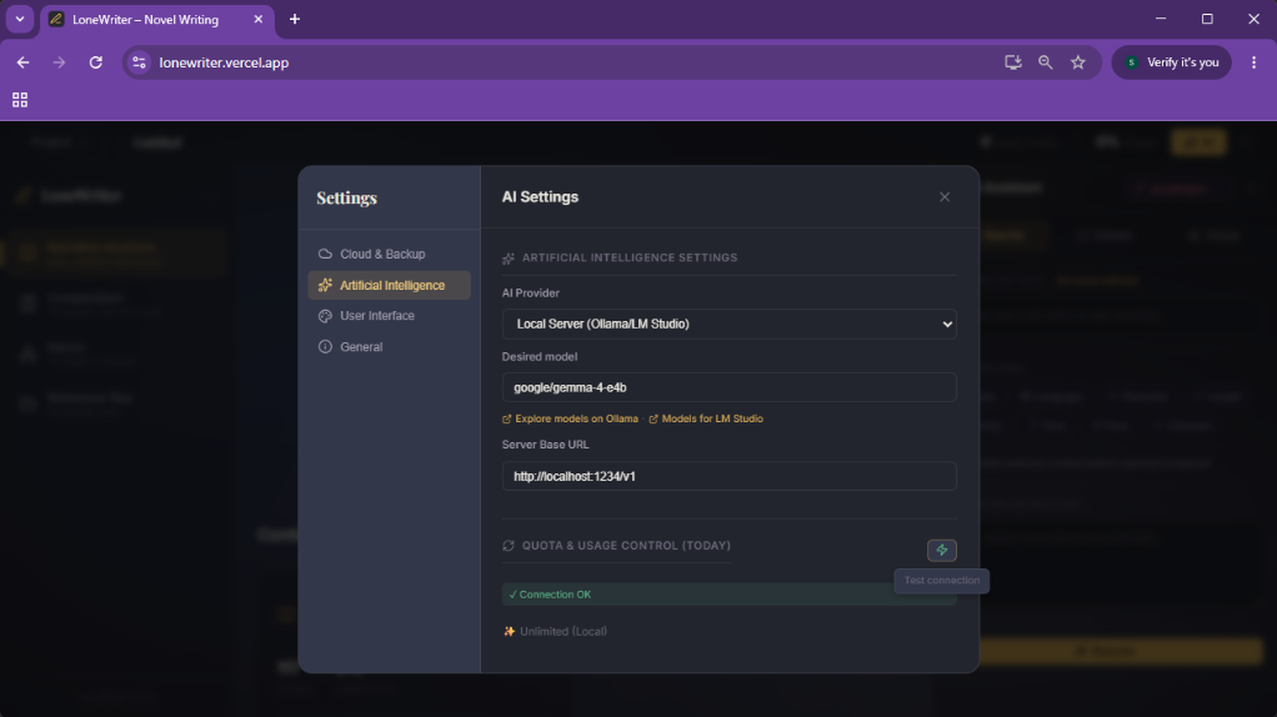
- En LoneWriter, ve a Ajustes > Inteligencia Artificial.
- Selecciona el proveedor Local.
- En el campo Servidor URL, pega la URL copiada de LM Studio (normalmente
http://localhost:1234/v1ohttp://127.0.0.1:1234/v1). - En el campo Modelo, pega el API Model Identifier.
- Asegúrate de añadir
/v1al final de la URL si LM Studio no lo ha incluido automáticamente (ej.http://localhost:1234/v1). - Confirma la conexión pulsando el botón de prueba.
Requisitos de Hardware
La ejecución de modelos locales requiere recursos significativos:
- 8GB RAM: Modelos pequeños (1B - 3B parámetros).
- 16GB RAM: Modelos estándar (7B - 8B parámetros).
- 32GB RAM o superior: Modelos avanzados.
CONSEJO
Si tu equipo tiene dificultades con los modelos locales, puedes optar por modelos en la nube. Consulta la Guía de Selección de Modelos para entender las diferencias de rendimiento y privacidad.
Siguiente paso
Una vez configurada su conexión, aprenda a utilizar el Editor de LoneWriter para dar vida a su historia.